Exploring and Validating S3 Data Using Firebolt's Table-Valued Functions

TL;DR: Batch Ingestion often involves copying files into a data warehouse from Amazon S3. There are numerous challenges that can introduce errors and inefficiencies, requiring manual intervention. However, with Firebolt's table-valued functions like LIST_OBJECTS, READ_CSV, and READ_PARQUET, you can query and explore your data directly in its original format on S3 before committing to ingestion. This article explores how to use these functions effectively to automate data quality checks, reduce errors and streamline your data ingestion pipelines.
In typical cloud data warehouse operations, the following issues can cause data pipeline failures:
- File format mismatches: Ingesting a file without understanding its schema or content leads to data type conflicts.
- Unexpected file sizes or missing data: Files may be incomplete, corrupt, or contain unexpected data.
- Misconfigured paths: Incorrect S3 paths can lead to ingestion failures or pulling the wrong data.
By using Firebolt's built-in table-valued functions , pre-defined database functions that return a table as their output, you can mitigate these issues by exploring your data before ingesting it.
1. Listing Objects in S3
Before reading or ingesting data, you need to know how folders (prefixes) and files (objects) are organized in your S3 bucket. LIST_OBJECTS is a Firebolt SQL function that lets you view the contents of an S3 bucket, enabling you to check for the existence, size, last modified timestamp and type of files.
Example: Listing All Objects in an S3 Bucket
SELECT *
FROM LIST_OBJECTS('s3://firebolt-sample-datasets-public-us-east-1/ecommerce_primer/parquet/'
);In this query, you're providing the S3 bucket path (AWS credentials are optional as it is a public bucket). The function will return a list of files in the bucket, including:
- object_name: The name of the file.
- object_type: Whether the object is a file or a folder (folders are referred to as “prefixes” in AWS documentation)
- size_in_bytes: The size of the file.
- last_modified: The timestamp of when the file was last modified.
This information helps you confirm that the correct files are present and can reveal potential issues like missing or incomplete files.

How This Helps
By listing objects before ingestion, you eliminate errors related to missing files, incorrect paths, or unexpected file sizes. For example, if a file you're expecting is missing, you can address that before attempting ingestion.
2. Exploring CSV Data
The next step in the data exploration process is examining the structure of the files you want to ingest. For CSV files, Firebolt’s READ_CSV function allows you to directly query the contents of a CSV file stored in S3. The READ_CSV function provides most of the same options that you have when ingesting data using COPY FROM, such as specifying a header row, handling quotes, etc.
This is important because it highlights how built-in table-valued functions like READ_CSV can seamlessly integrate with other language constructs and features. For instance, you can use READ_CSV not only for exploration but also for ingestion by combining it with other SQL operations, such as INSERT INTO t SELECT * FROM read_csv(...). This demonstrates that the capabilities provided during data ingestion are inherently part of the function itself, streamlining workflows and reducing the need for separate ingestion-specific references.
Example: Previewing a CSV File
SELECT *
FROM READ_CSV('s3://firebolt-sample-datasets-public-us-east-1/nyc_sample_datasets/nycparking/csv/17C226C1CB54CCC9_1_0_0.csv')
LIMIT 10;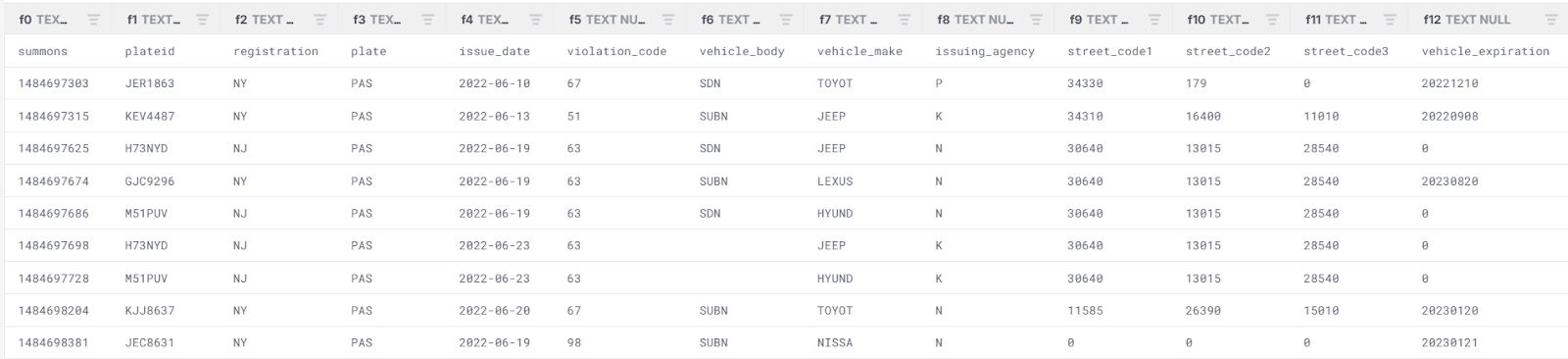
This query reads the first 10 rows of the specified CSV file. You can also configure additional parameters such as:
- header: Skips the first row if the CSV file includes headers.
- delimiter: Specifies the character that separates values (e.g., commas for CSV files).
How This Helps
Reading CSV data before ingestion allows you to:
- Check for proper formatting (e.g., ensuring no missing delimiters).
- Verify the integrity of the data.
- Ensure that the data types are consistent with your target schema (e.g., numeric values where expected).
- Experiment with different formatting options and examine the outputs
Explore the data before ingestion to prevent common errors like column misalignments or incorrect data types that often occur when ingesting CSV files directly.
3. Exploring Parquet Data
For columnar data formats like Parquet, which are commonly used for large datasets due to their efficiency in storage and querying, Firebolt provides the READ_PARQUET function. This allows you to explore the structure of a Parquet file and ensure its schema matches your expectations.
Example: Previewing a Parquet File
SELECT *
FROM READ_PARQUET('s3://firebolt-sample-datasets-public-us-east-1/ecommerce_primer/parquet/ecommerce_2_3_94.gz.parquet')
LIMIT 10;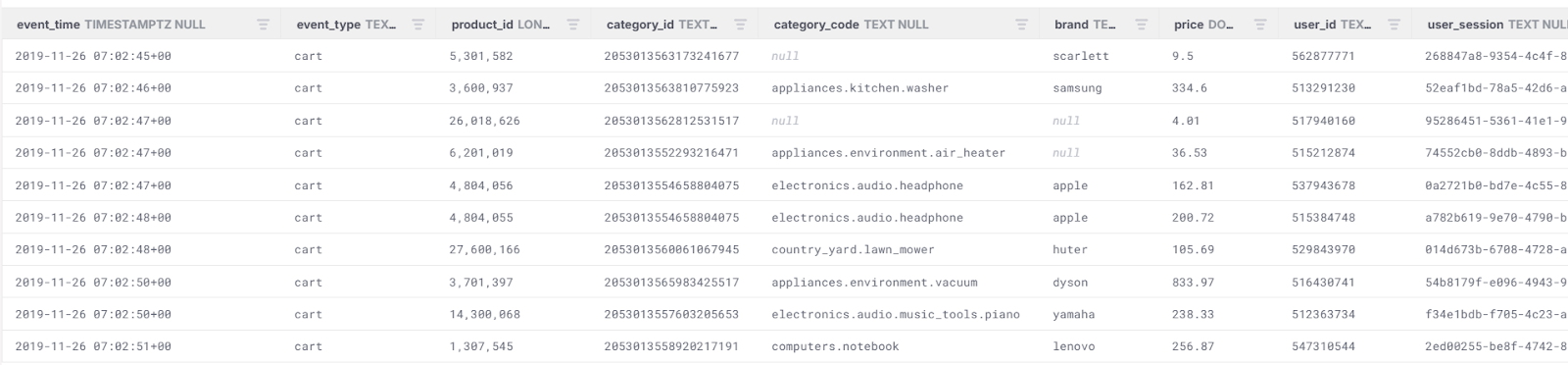
Similar to the READ_CSV function, this query returns the first 10 rows from the Parquet file, allowing you to explore its contents.
How This Helps
By querying Parquet data directly, you can:
- Inspect the schema, including column names and data types.
- Verify data integrity and check for missing or corrupt data.
This function helps prevent ingestion errors related to schema mismatches, which can be particularly problematic when dealing with the more complex structure of Parquet files.
4. Automating data validation prior to ingestion
These three table-valued functions (LIST_OBJECTS, READ_CSV, READ_PARQUET) enable a more proactive approach to data ingestion by allowing exploration before ingestion. This helps ensure that the data you’re ingesting is correct, well-structured, and consistent with the target schema, thereby reducing the risk of errors that could disrupt downstream analytics or machine learning workflows.
Example: Combining Functions for End-to-End Validation
Imagine you're ingesting multiple CSV and Parquet files from an S3 bucket. By combining these functions, you can build a process that validates the data before ingestion.
-- List all objects in the folder
SELECT *
FROM LIST_OBJECTS('s3://my-data-bucket/data-folder/');
-- Preview the first 10 rows of a CSV file
SELECT *
FROM READ_CSV('s3://my-data-bucket/data-folder/sample.csv', ‘’ , 'aws_access_key_id', 'aws_secret_access_key')
LIMIT 10;
-- Preview the first 10 rows of a Parquet file
SELECT *
FROM READ_PARQUET('s3://my-data-bucket/data-folder/sample.parquet', 'aws_access_key_id', 'aws_secret_access_key')
LIMIT 10;
This workflow allows you to verify the contents and structure of each file before moving forward with ingestion, reducing the chances of costly errors.
Using Python, you can programmatically check file integrity, preview file contents, and validate schema consistency for both CSV and Parquet files stored on S3.
Example: Using Python with Firebolt
Here’s how you can integrate these Firebolt functions into a Python script:
import pandas as pd
import os
from dotenv import load_dotenv
import numpy as np
from firebolt.db import connect
from firebolt.client.auth import ClientCredentials
# Set Firebolt credentials and table info
load_dotenv()
FIREBOLT_DATABASE = os.getenv("FIREBOLT_DATABASE")
FIREBOLT_TABLE = os.getenv("FIREBOLT_TABLE")
FIREBOLT_USER = os.getenv("FIREBOLT_USER")
FIREBOLT_PASSWORD = os.getenv("FIREBOLT_PASSWORD")
FIREBOLT_ACCOUNT = os.getenv("FIREBOLT_ACCOUNT")
FIREBOLT_ENGINE = os.getenv("FIREBOLT_ENGINE")
FIREBOLT_API_ENDPOINT=os.getenv("FIREBOLT_API_ENDPOINT")
# Connect to Firebolt
connection=connect(
engine_name=FIREBOLT_ENGINE,
database=FIREBOLT_DATABASE,
account_name=FIREBOLT_ACCOUNT,
auth=ClientCredentials(FIREBOLT_USER, FIREBOLT_PASSWORD),
api_endpoint=FIREBOLT_API_ENDPOINT,
)
cursor = connection.cursor()
table_name = 'ecommerce'
try:
# Get the list of columns from the table
cursor.execute(f"DESCRIBE {table_name};")
expected_columns = [row[1] for row in cursor.fetchall()]
if len(expected_columns)==0:
print ("No table info found")
cursor.close()
connection.close()
exit()
else:
print(f"Table Columns: {expected_columns}")
except Exception as e:
print(f"Error fetching table columns: {e}")
cursor.close()
connection.close()
exit()
# List S3 objects
try:
cursor.execute("""
SELECT *
FROM LIST_OBJECTS(
's3://firebolt-sample-datasets-public-us-east-1/ecommerce_primer/parquet/'
);
""")
objects_df = pd.DataFrame(cursor.fetchall(), columns=[desc[0] for desc in cursor.description])
if objects_df.empty:
print("No files found in the S3 bucket.")
cursor.close()
connection.close()
exit()
except Exception as e:
print(f"Error fetching S3 objects: {e}")
cursor.close()
connection.close()
exit()
# Loop through each object and process based on file type
print (f"Number of files found:{len(objects_df.index)}")
for index, row in objects_df.iterrows():
print(f" {index}/{len(objects_df.index)} Processing file: {row['object_name']}")
# Check if file is CSV or Parquet and run the corresponding function
if row['object_name'].endswith('.csv'):
try:
cursor.execute(f"""
SELECT *
FROM READ_CSV('s3://firebolt-sample-datasets-public-us-east-1/nyc_sample_datasets1/nycparking/csv/17C226C1CB54CCC9_1_0_0.csv')
LIMIT 10;
""")
csv_sample_df = pd.DataFrame(cursor.fetchall(), columns=[desc[0] for desc in cursor.description])
csv_missing_cols = set(expected_columns) - set(csv_sample_df.columns)
if csv_missing_cols:
print(f"Missing columns in CSV: {csv_missing_cols}")
else:
print("CSV Preview:")
print(csv_sample_df)
except Exception as e:
print(f"Error reading CSV file {row['object_name']}: {e}")
elif row['object_name'].endswith('.parquet'):
try:
cursor.execute(f"""
SELECT *
FROM READ_PARQUET(
's3://firebolt-sample-datasets-public-us-east-1/{row['object_name']}'
)
LIMIT 10;
""")
parquet_sample_df = pd.DataFrame(cursor.fetchall(), columns=[desc[0] for desc in cursor.description])
parquet_missing_cols = set(expected_columns) - set(parquet_sample_df.columns)
if parquet_missing_cols:
print(f"Missing columns in Parquet: {parquet_missing_cols}")
else:
print("Parquet Preview:")
print(parquet_sample_df)
except Exception as e:
print(f"Error reading Parquet file {row['object_name']}: {e}")
cursor.close()
connection.close()
exit()
else:
print(f"Skipping unsupported file type: {row['object_name']}")
# Close connection
cursor.close()
connection.close()How This Helps
- Automation: Run these SQL queries via Python scripts to automatically validate S3 data before ingestion.
- Error detection: Ensure that the structure and content of the files meet the expected criteria (e.g., correct columns, file size limits).
- Scalability: Perform checks on multiple files or directories programmatically, reducing manual intervention.
This integration allows you to enforce robust quality checks and eliminate ingestion issues before they impact your data pipelines.
Conclusion
Data exploration is a crucial step in maintaining the integrity and accuracy of your data pipelines. By using Firebolt's LIST_OBJECTS, READ_CSV, and READ_PARQUET functions, you can explore and validate your data directly from S3, ensuring that any issues are caught early in the process. These lightweight, simple, and flexible table-valued functions streamline ingestion workflows through automation, saving time and money.
But what if your files contain errors? Firebolt’s COPY FROM command offers robust options to handle such scenarios. Features like ERROR_FILE and MAX_ERRORS enable you to ingest files with formatting issues while providing detailed error reports. These reports highlight what errors occurred and identify rejected rows, making troubleshooting straightforward and efficient.
By combining these powerful features—TVFs for exploration and COPY FROM for error-tolerant ingestion—you can take complete control of your cloud data workflows. This approach makes your data exploration and ingestion processes more robust, efficient, and error-free.
