

Listen to this article
Staying sane in the modern world of data engineering is a non-trivial mission. As data engineers we ask ourselves the same question several times a day: is everything okay with my data?
If you know what I’m talking about, you also know that, let's be honest, our primary concern is how to organize data processes and never see them again. So each time BI developers or analysts want to add a new transformation, query, or change some output schemas (oh, they do it a lot, don’t they?), this process ideally should not involve us - data engineers.
Here, at Firebolt, we actually managed to build something close to this dream. In the blog, we will introduce dbt briefly, followed by detailed instructions to set up and configure the model.
Peeling the onion

Let’s see what’s inside the onion. First of all, we use our product - Firebolt as our data warehouse. Yes, we are into dogfooding and drinking our own champagne, exciting stuff.
As with any data engineering plan, life starts at the source. Multiple ones at that. Here are some of the data sources we connect to.
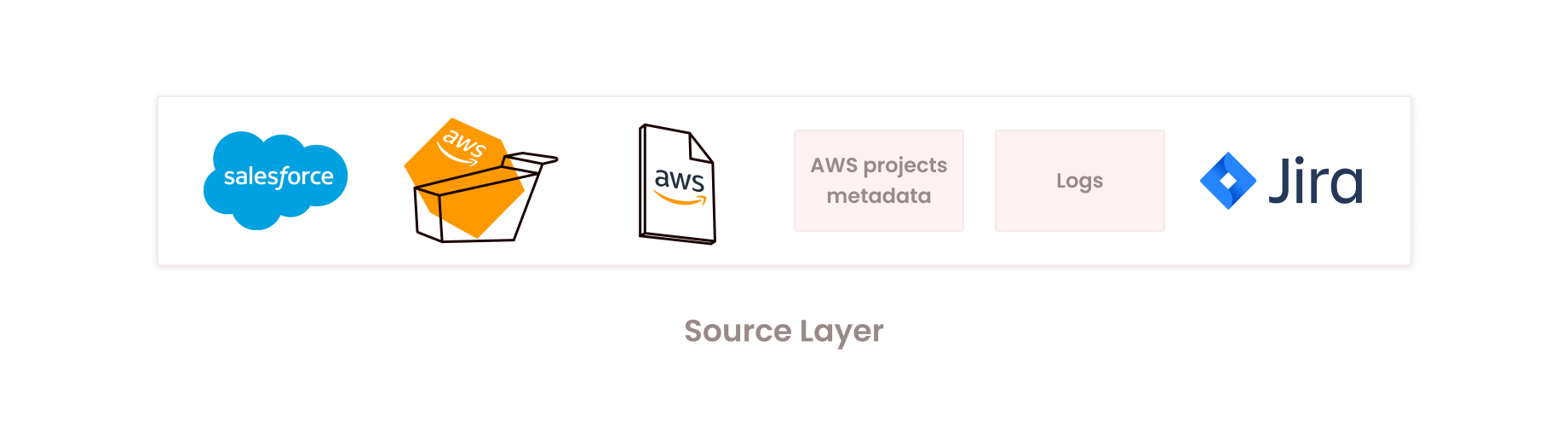
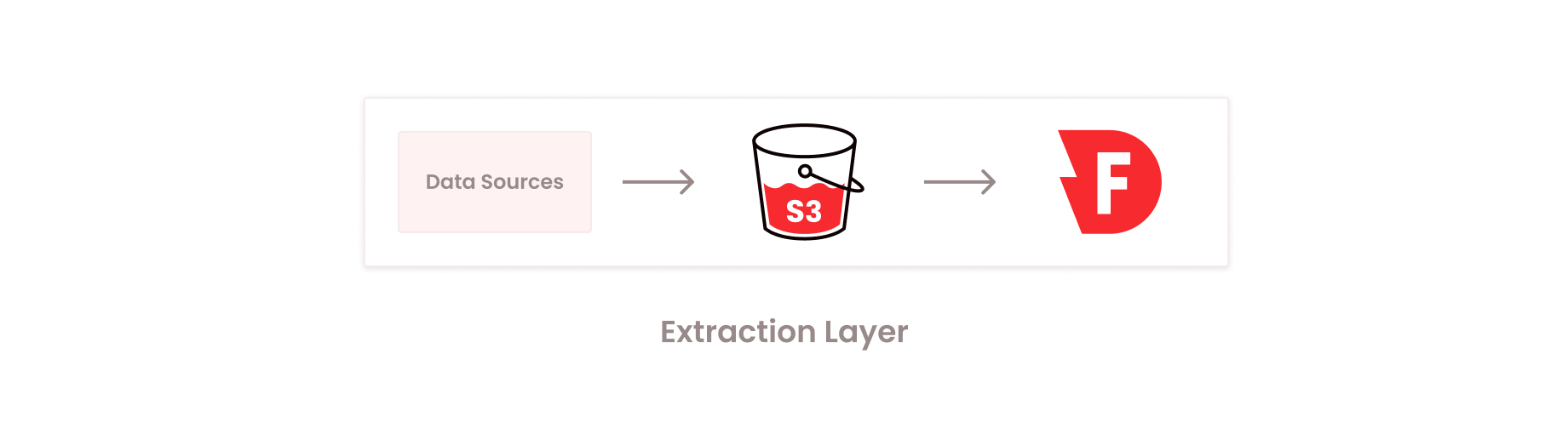
We use a microbatch/batch architectural pattern and our extraction processes save raw data as parquet files in Amazon S3, as intermediate storage, for ingestion into Firebolt.
Finally, we use Looker as our presentation layer. As a result, all the data should end up on the dinner table, ready for self service, for our final customers such as marketing or finance departments.

As you might have guessed there is another layer between extraction and presentation - transformation.
When you hear the word transformation you might think first about queries - lots of them, and it’s quite close to reality. Before data can be presented it should be verified, documented, aggregated, joined and finally passed through data quality checks. These steps take a lot of effort from the engineering side.

We chose dbt to cover all these needs.

Think of dbt as a black box where you feed raw data and get transformed data. Not familiar with dbt? More in the next section …
dbt in a nutshell

I have read a lot of articles about what dbt is and a lot of them have something in common: too many buzzwords and too few clear explanations. dbt is an open-source “data build tool” that you can install on your computer for free or run from the dbt cloud for a fee.
dbt works with your data and executes transformations within the warehouse so the data never goes elsewhere. It builds a Directed Acyclic Graph (DAG) from your SQL queries and/or Python code, then runs them to materialize results in the form of tables/views using overwrite or incremental strategies.
Additionally, dbt gives a wide range of packages, hooks and macros to transform data. Do you want to save a snapshot of your resulting data or maintain previous states? How about quality and freshness checks on your data? dbt can help with all that. The dreaded, ‘Do I have to document this thing that I created?’; no worries, dbt can help.
Another way to say it, dbt provides complete control over your data. How is dbt deployed? There are a few different options: run it locally on your computer, deploy it in a container running on Kubernetes or run it in the dbt Cloud.
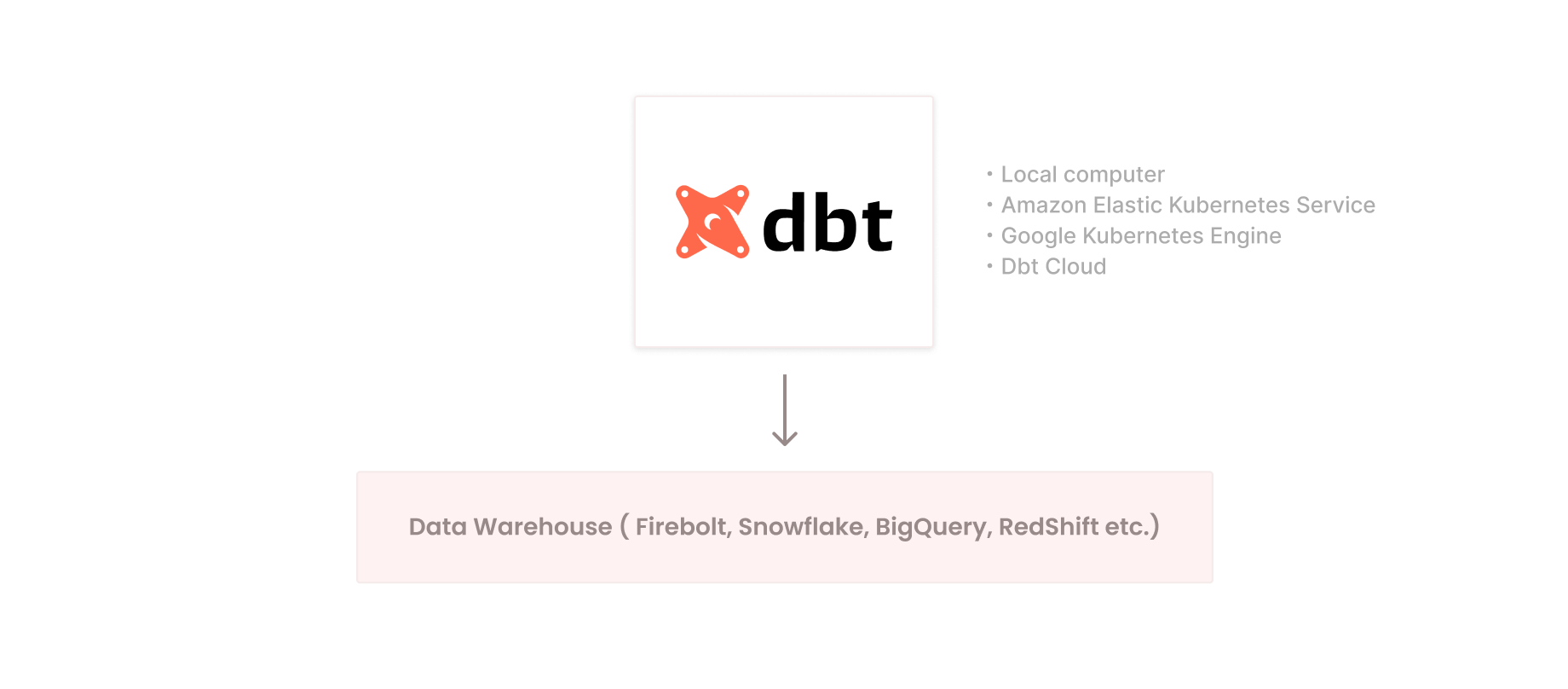
No matter where dbt is located, it works with data through the data warehouse scope.
Now that dbt is deployed, the next two steps take us into configuring dbt and creating transformations.
How to configure dbt?
After you decide where you want to run dbt, the next step is to configure your dbt project. To do that you need to specify configurations in the dbt_project.yml file.
Besides that you have to specify different settings, you also have to tell dbt how to connect to the warehouse. You can connect dbt to the different warehouses using ‘profiles’ and ‘targets’ settings, one profile per one warehouse. Each profile can consist of many targets so you can even organize your development environments through them.
When dbt connects to data warehouses it uses adapters; you can find a list of supported adapters here.
What do we want to do with our data?
Within the dbt project, transformations are organized in the form of models. dbt offers two types of models: SQL models and Python models. A SQL model is a SQL SELECT statement that is specified in a file using .sql extension while the python model uses a .py extension. These files are stored under the models directory within the project.
Once you write a model, you can use it anywhere by referring to it on other models. So, in the end we get the DAG of the models that can be verified, built, and tested.
How do you organize your models? You can find recommendations on how to structure your project in the best practices section of dbt documentation. We organized the models in three layers as shown below.
- Staging
Staging models should have a 1-to-1 relationship to our source tables with the help of the source macro. This is the layer where you clean the data with basic transformations like type casting, simple computations, categorizing etc, but you don’t join or group.
- Intermediate
A middle layer between staging and marts. If your models are complicated, sometimes you need to reuse the middle result.
- Marts
Final entities that are presented to users. That’s the place for joins and groups.
Let’s look at the example of the dbt DAG below that was created according to the mentioned recommendation.
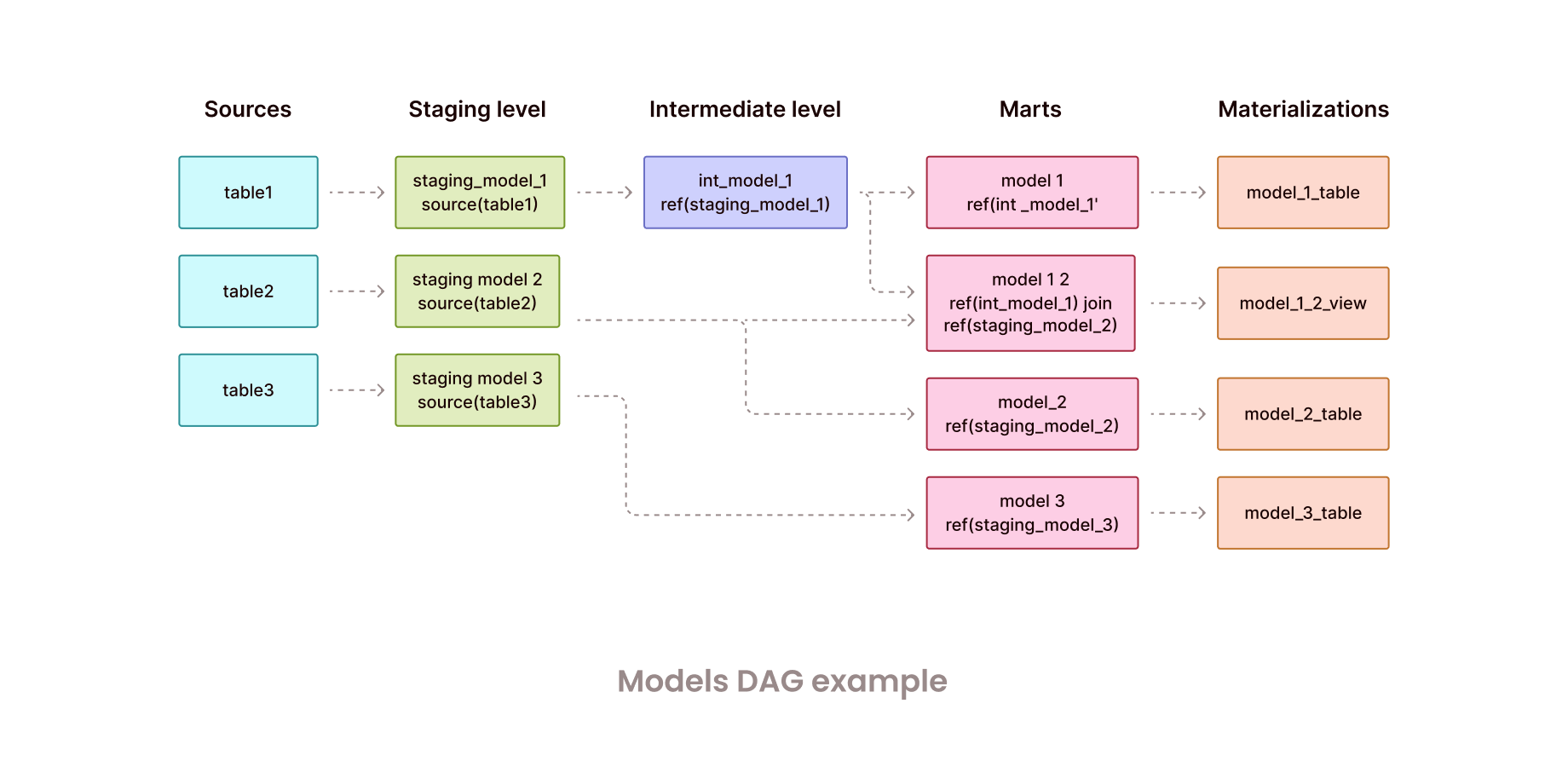
Here we have 3 sources: table1, table2, and table3. On the staging level we connect the models to these sources through the source macro. Then there is one intermediate model that refers to staging_model_1, then there are 4 marts with references to the previous models and finally, they materialize into 3 tables and 1 view.
dbt will run staging_model_x models, then int_model_1, and then model_x.
What does “run” mean in the context of dbt? As mentioned earlier, a dbt model is a SELECT statement in a .sql file. Running a model implies running the select statement and materializing the results into one of four types supported by dbt: tables, views, ephemerals, and incrementals.
Let us look at the staging_model_2.sql from the above example. At the beginning of the file, you specify how the results of the query are materialized. In this case, this is a view.
This statement, when run, executes a CREATE VIEW staging_model_2 statement in the warehouse. It selects rows that are newer than “2022-01-01” from table_2. Once this model is run, this can be referenced in other models. In the above example, model_2 references the staging model and the model_2.sql file is shown below.
This is equivalent to executing a CREATE TABLE model_2 in the data warehouse and storing the result set of SELECT * from staging_model_2 view into model_2 table.
{{rich-mid-cta="/stylesheet"}}
dbt project - chop chop
Lets dive deeper into a simple case with only one model, to demonstrate how easy it is to organize and run a dbt project. Rest of the article will cover creating this environment on your local machine and transforming data. At Firebolt, we use approximately the same project structure, with a larger number of sources and models.

For this case, I used synthetic application logs that contain id, ip_address, event_time, app, url, and country columns. First, I need to ingest the logs to a table in Firebolt and use it as the only source for my dbt project. You can find ingestion queries example here.
Data sample:
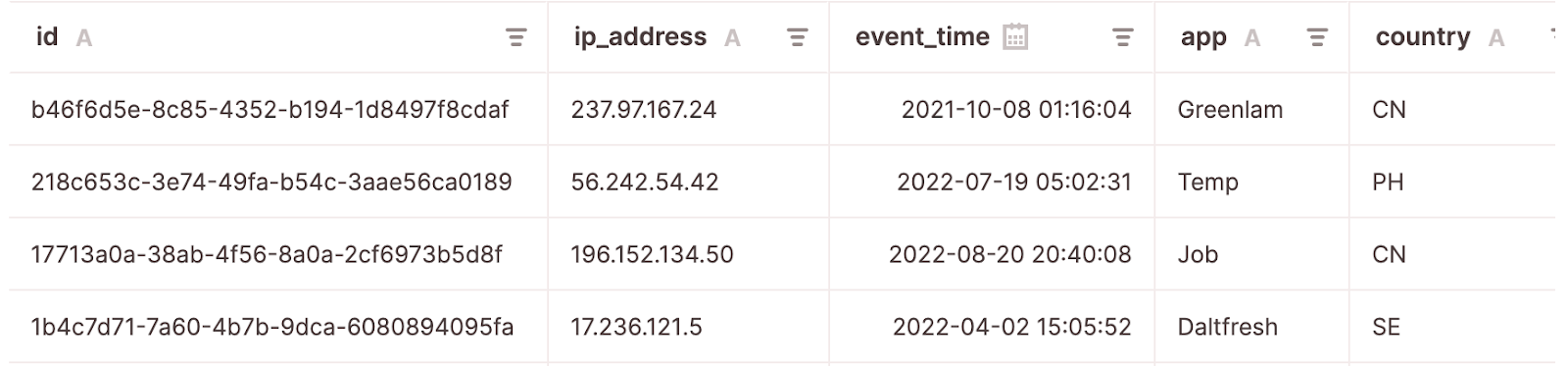
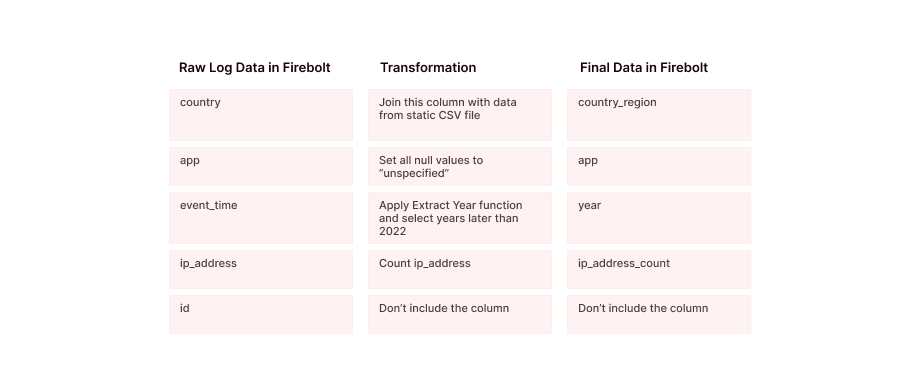
I expect a table in Firebolt with data that is newer than “2022-01-01” and the following columns with the appropriate transformations. A CSV file to augment data will be described in the next section along with the appropriate dbt steps.
Getting started with dbt on Firebolt
This tutorial covers the local setup of dbt with the Firebolt adapter. Initially, we need a folder for our project and a python virtual environment. You can use any python package that you like for virtual environments. This example is provided for MacOS.
- Install pyenv
brew install pyenv
brew install pyenv-virtualenv
- Install python
pyenv install 3.10.0
- Create a virtual environment
pyenv virtualenv 3.10.0 dbt_project
- Create a project directory
mkdir dbt_project
- Connect dbt_project virtual environment with the project folder:
cd dbt_project
pyenv local dbt_project
- Install the dbt adapter of the warehouse that you’re going to use.
pip install dbt-firebolt==1.1.2
pip install dbt-core==1.1.2
Project structure
First, let’s establish the connection between dbt and Firebolt. You can find more information about the dbt Firebolt adapter here.
- Create profiles.yml file in the project directory.
touch profiles.yml
- To connect to the data warehouse, create a profile called “firebolt” by adding the highlighted text below to the profiles.yml file.
firebolt:
I created only the “default” target with a connection to my database, but you can add more targets like dev/prod/i_love_cats. Connection type is set to Firebolt. Credentials are required to connect to the Firebolt data warehouse. These are passed through environment variables as shown.
For local development you can create a .env file and supply it with values. Don’t forget to add .env to the .gitignore file to avoid those situations when you share sensitive information with the outside world.
- Now that we have our connection, we create a dbt_project.yaml file in the project directory. Add yaml code below into this file. In the dbt_project.yaml file, we configure seed-paths and model-paths. Seeds are static data files that dbt can use to create tables in a data warehouse. Seed paths and Model paths refer to the directory structure that we will create to store these files in a subsequent step. You might notice the var section with start_year: '2022'. I will use it later in my queries.
Also it is worth mentioning that in our company we also split models not only by logical levels but also by workspaces. Here, for example, we have a “warehouse” workspace with analytics models inside, in the real world I could have other workspaces like “monitoring” or “finance_team”. It allows you to split the environment between teams keeping all company’s models in a monorepo. Finally, because our demo is simple, we will use only 2 layers: staging and marts.
- Create the following folders in the project directory. This folder structure mirrors the config above in dbt_project.yml file:
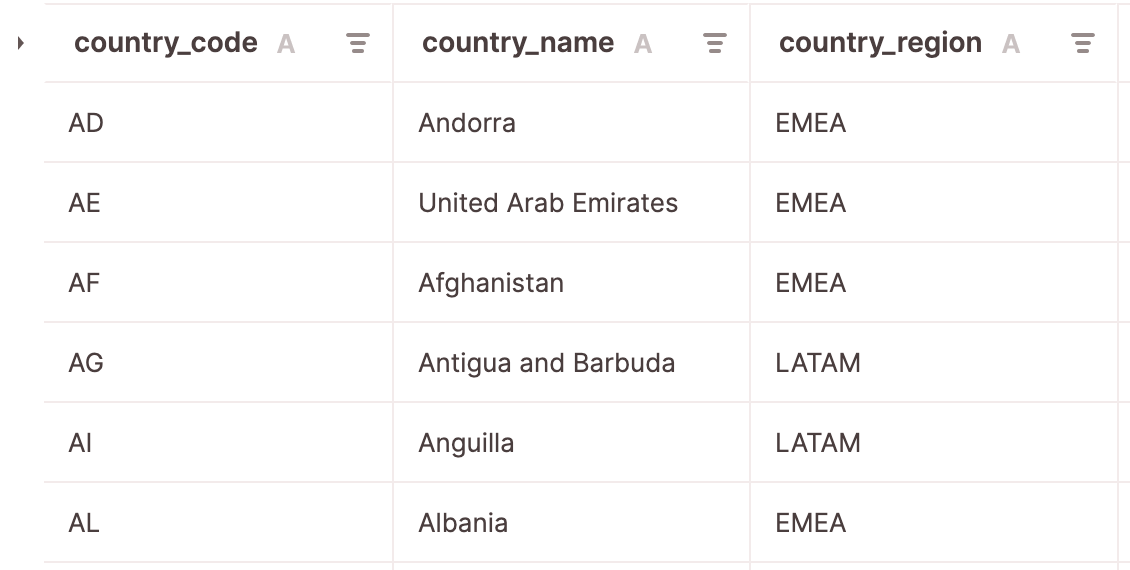
- Next, we will use a csv file with relations between country codes, countries, and country regionst as a seed. This seed file will be used to create a translation table to obtain country regions.
- Now it is time to test the connection to the data warehouse.
Export our .env file.
And run
dbt debug

Great! We’re connected successfully so we can write models. But first I would like to create my seed table with country regions.
dbt seed
Let’s check what we got in Firebolt
SELECT * FROM countries_by_region LIMIT 6
- We have the target, profile and seed. Let’s describe our source, so first we need to create a “source” folder.
mkdir -p models/workspaces/sources
In this directory, I create a scr_logs.yaml file that describes the logs table.
In this file you can also:
- Check on source data freshness
- Test and Document the source
- Almost the last step - queries.
For starters, the staging model is created in stg_logs.sql file with the query shown below. This extracts year columns and sets all NULL apps as “unspecified”. This staging level uses ephemeral materialization by default as specified in the dbt_project.yaml.
Path to model file: models/workspaces/warehouse/analytics/staging/logs/stg_logs.sql
Let’s provide a user-defined description to a final model in a yaml file. You can define other sub-properties in the same file. For example, if you want to add a test for not null values look at the year column shown below
PATH:models/workspaces/warehouse/analytics/marts/apps/apps_f.yml
Now it’s time for a final model. I’m going to join data from the staging level with our seed table to get a country region column. Also I use the variable '{{ var("start_year") }}'
that I defined in the project config file, since dbt allows you to save constants in one place.
PATH:models/workspaces/warehouse/analytics/marts/apps/apps_f.sql
That’s it, we are ready to run dbt.
dbt run
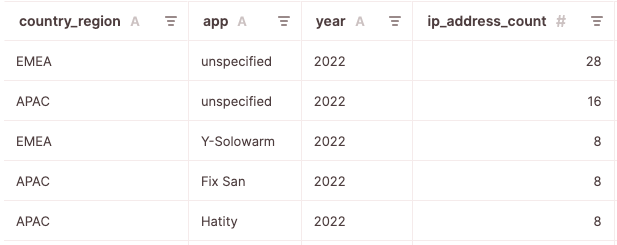
Let’s check our table.
SELECT * from apps_f order by ip_address_count desc limit 5
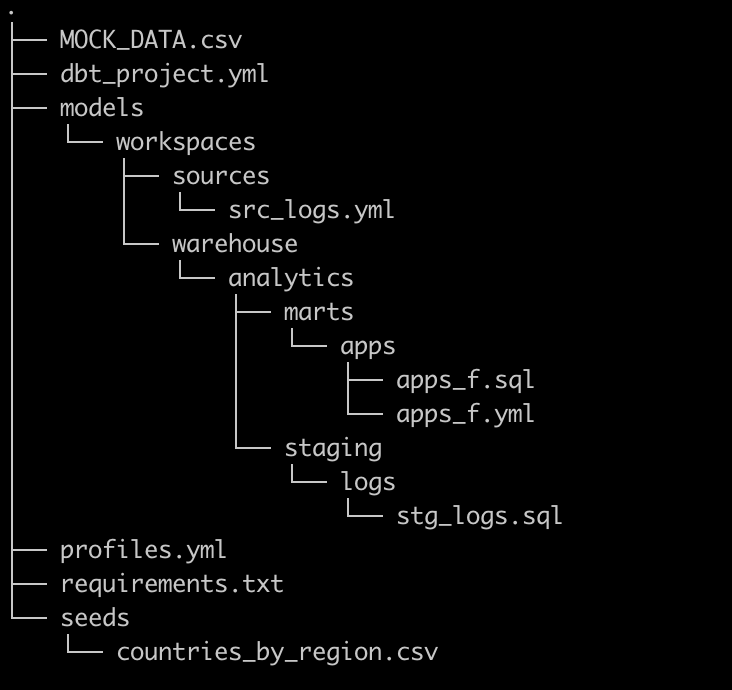
To summarize what we did in the chapter, let’s review our project structure.
- dbt_project.yml - dbt project configs
- profiles.yml - connections to data warehouses
- models - SQL queries
- User-defined descriptions
- seeds - static csv files
The dbt project structure looks as shown here with the supporting files.
You can find code for this project in github repo
From local development to real business

So now we have a local setup, what’s next? We need to share the setup with other engineers.
Let’s add some docker here. Running this setup in a docker image also provides us portability, simplicity of deployment and the choice of orchestration. Here are the steps for dockerizing.
Install Docker Desktop and run it.
Next, let’s put our requirements into requirements.txt file for Python.
Example of Dockerfile is shown below. I set the DBT_PROFILES_DIR environment variable to provide a path to profiles.yml file.
Create a docker image.
docker build --tag dbt_project .
And now you can run any dbt command.
docker run -it --env-file .env --publish 8080:8080 dbt_project dbt debug
docker run -it --env-file .env --publish 8080:8080 dbt_project dbt run
You can upload a docker image to any image registry and use it locally or on your servers, kubernetes, airflow etc.
At Firebolt, we use Argo Workflows for orchestration, so we just have a container template that uses the dbt docker image uploaded to a container registry. Instead of a .env file we apply ConfigMap with the same env variables and Secret for credentials on the kubernetes cluster.
Too perfect, what's the catch?
The above configuration is awesome for engineers. What about people who don’t have experience with Github, command line, and Docker?

It means you should invest a huge amount of time to share your knowledge on how to use github, IDEs, and docker images. Or, just use Paradime!
Paradime comes to the rescue
Using dbt in a docker image with models was not enough. We needed ease of use for a broader user base. To address this, we decided to use Paradime. Paradime serves as a cloud IDE for dbt with visibility into various dbt models and adds lineage, catalog and GitHub integration. All in a simple, easy to use webui. This addresses the needs of the data practitioners and the analysts that work on our team. Let’s take a closer look at some of the key features of Paradime we use.
Paradime has the concept of environments within each account. This helps us segregate production and development environments, each with its standardized set of connections to databases. With this approach, users can use environments out of the box. Figures below show environment and database connection setup. Connection reflects profiles.yml from a dbt perspective.
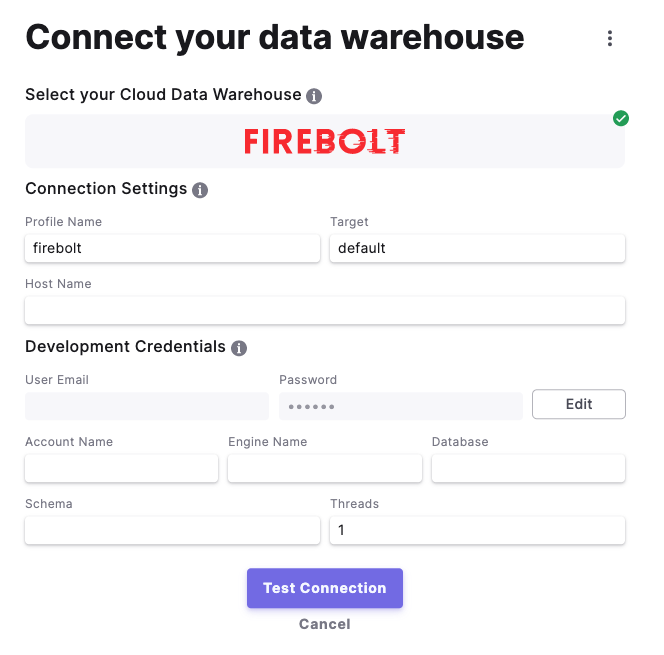
Paradime provides a Code Editor with built-in GitHub integration. Using a deploy key you can connect your dbt git repository with Paradime and observe files in its Code Editor in your browsers. It looks quite similar to VS Code. Moreover it has a built-in git client in the same window where you can review your changes and push them to git.
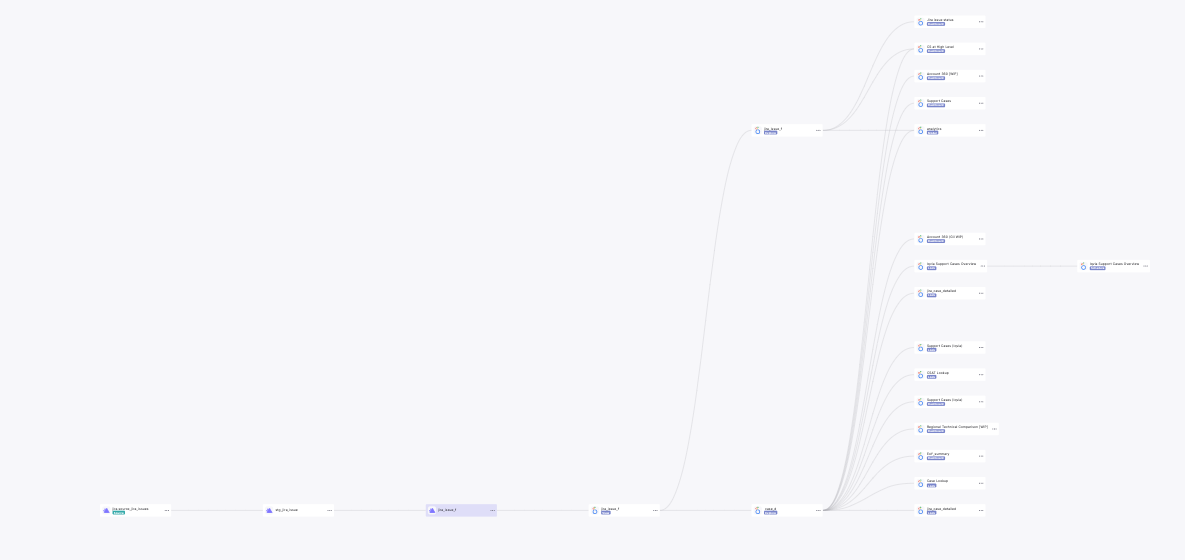
Also, Paradime has a Lineage feature that provides you with DAG visualization. You can look for a specific model to get all references. Paradigm lineage can be extended beyond dbt to include data integration and BI tools. In our case, we are able to extend our lineage all the way to Looker, giving us the ability to assess downstream impact of upstream changes.
Recently, Paradime has added the ability to schedule dbt runs eliminating the need for other third party tools. Integrations are also available for Airflow, Prefect and Dagster in the form of external orchestrators. Currently, we use Argo Workflows for scheduling and will look at this new Paradime feature in the future.

Putting it all together
Every development and data engineering team is different. In our case, we wanted to enable our team with the right set of tools and automation to help manage data integrations. With that in mind, what we have delivered is a best of breed solution that combines dbt and Paradime along with GitHub integration to simplify the development and deployment. Our process now flows as below.
- dbt project lives in the github repository that is connected to Paradime.
- Users work with dbt models through Paradime. After they completed the development and testing stage, all the changes are pushed to our dbt github repo.
- Each merge to the main branch triggers a Github Action script that builds a new docker image under a new tag version and uploads it to our container repository.
- Argo Workflows run dbt models at different hours using a docker image that is pulled from the container repository.
Wrapping up
At Firebolt, we found out that a duet of dbt and Paradime works for our needs. dbt saves data engineer’s time significantly and provides many features to handle our data. We added Paradime to lower the barrier to entry with dbt development, providing easy and fast hands-on work with visibility across all our pipelines. Interested in knowing more, feel free to reach out to us.
